This is a lab project from a machine learning course which focuses on anomaly detection. While anomaly detection is often seen as an unsupervised task, this project takes a different approach by tackling it as a multi-label classification problem. The dataset comprises IT systems monitoring data, processed by a monitoring system to detect various anomalies. The goal is to build machine learning models capable of accurately identifying these anomalies. It also emphasizes the importance of interpretability, given the significance of understanding model outputs in anomaly detection applications.
Information about the dataset
Attributes
- SessionNumber (INTEGER): it identifies the session on which data is collected;
- SystemID (INTEGER): it identifies the system generating the data;
- Date (DATE): collection date;
- HighPriorityAlerts (INTEGER [0, N]): number of high priority alerts in the session;
- Dumps (INTEGER [0, N]): number of memory dumps;
- CleanupOOMDumps (INTEGER) [0, N]): number of cleanup OOM dumps;
- CompositeOOMDums (INTEGER [0, N]): number of composite OOM dumps;
- IndexServerRestarts (INTEGER [0, N]): number of restarts of the index server;
- NameServerRestarts (INTEGER [0, N]): number of restarts of the name server;
- XSEngineRestarts (INTEGER [0, N]): number of restarts of the XSEngine;
- PreprocessorRestarts (INTEGER [0, N]): number of restarts of the preprocessor;
- DaemonRestarts (INTEGER [0, N]): number of restarts of the daemon process;
- StatisticsServerRestarts (INTEGER [0, N]): number of restarts of the statistics server;
- CPU (FLOAT [0, 100]): cpu usage; PhysMEM (FLOAT [0, 100]): physical memory;
- InstanceMEM (FLOAT [0, 100]): memory usage of one instance of the system;
- TablesAllocation (FLOAT [0, 100]): memory allocated for tables;
- IndexServerAllocationLimit (FLOAT [0, 100]): level of memory used by index server;
- ColumnUnloads (INTEGER [0, N]): number of columns unloaded from the tables;
- DeltaSize (INTEGER [0, N]): size of the delta store;
- MergeErrors BOOLEAN [0, 1]: 1 if there are merge errors;
- BlockingPhaseSec (INTEGER [0, N]): blocking phase duration in seconds;
- Disk (FLOAT [0, 100]): disk usage;
- LargestTableSize (INTEGER [0, N]): size of the largest table;
- LargestPartitionSize (INTEGER [0, N]): size of the largest partition of a table;
- DiagnosisFiles (INTEGER [0, N]): number of diagnosis files;
- DiagnosisFilesSize (INTEGER [0, N]): size of diagnosis files;
- DaysWithSuccessfulDataBackups (INTEGER [0, N]): number of days with successful data backups; DaysWithSuccessfulLogBackups (INTEGER [0, N]): number of days with successful log backups;
- DaysWithFailedDataBackups (INTEGER [0, N]): number of days with failed data backups;
- DaysWithFailedfulLogBackups (INTEGER [0, N]): number of days with failed log backups;
- MinDailyNumberOfSuccessfulDataBackups (INTEGER [0, N]): minimum number of successful data backups per day;
- MinDailyNumberOfSuccessfulLogBackups (INTEGER [0, N]): minimum number of successful log backups per day;
- MaxDailyNumberOfFailedDataBackups (INTEGER [0, N]): maximum number of failed data backups per day;
- MaxDailyNumberOfFailedLogBackups (INTEGER [0, N]): maximum number of failed log backups per day;
- LogSegmentChange (INTEGER [0, N]): changes in the number of log segments.
Labels
Labels are binary. Each label refers to a different anomaly.
- Check1;
- Check2;
- Check3;
- Check4;
- Check5;
- Check6;
- Check7;
- Check8;
Data Exploration
My teammate and I explored the dataset and noticed:
- We can think this challenge as 8 binary-classification models or as 1 multiclass-classification model.
- Useless attributes to be removed from the model:
- ID-alike attributes: SessionNumber, SessionID
- Date (the date of data collection)
- All values are zeros: CleanupOOMDumps, PreprocessorRestarts, DaemonRestarts
- 25/44 columns contain missing values: 8 labels, BlockingPhaseSec (~26.4%), LogSegmentChange (~12.3%), CPU (~8.8%), etc.
- Data contains errors and outliers
There were two approaches to solve this challenge: a multiclass classification model or 8 binary classification models. However, the first one would create extremely imbalanced classes, with several classes having no value. Therefore, we decided to proceed with the second approach – 8 binary classification models (each label refers to a different anomaly). The imbalance problem still existed, but it was not as severe as in the first approach. In the second approach:
- Model 1 (label Check1) has 1% anomaly.
- Model 2 (label Check2) has 3% anomaly.
- Model 3 (label Check3) has 3% anomaly.
- Model 4 (label Check4) has 10% anomaly.
- Model 5 (label Check5) has 1% anomaly.
- Model 6 (label Check6) has 29% anomaly.
- Model 7 (label Check7) has 3% anomaly.
- Model 8 (label Check8) has 1% anomaly.
Categorical feature exploration
After removing the useless features, we were left with two categorical features: SystemID and MergeErrors. We considered the percentage of each anomaly in these features.


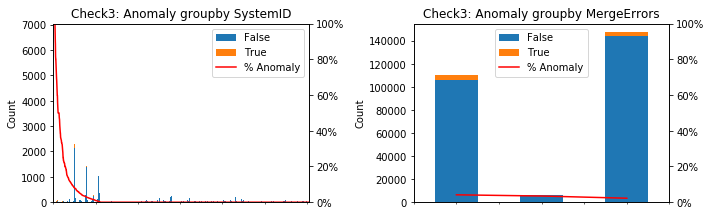




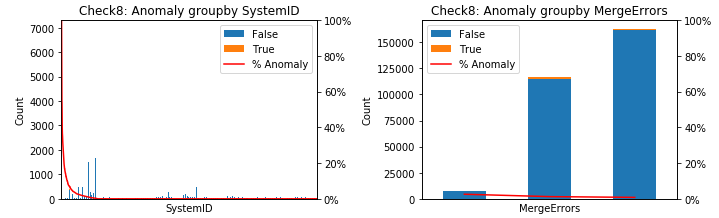
As can be seen from the plot of SystemID–Check4 and the plot of SystemID–Check6, there are several _SystemID_s which have the high percent of anomaly. That means perhaps there are problems inside some systems which caused the anomalies.
Numerical feature exploration
First, we explored the relationships between the numeric attributes.
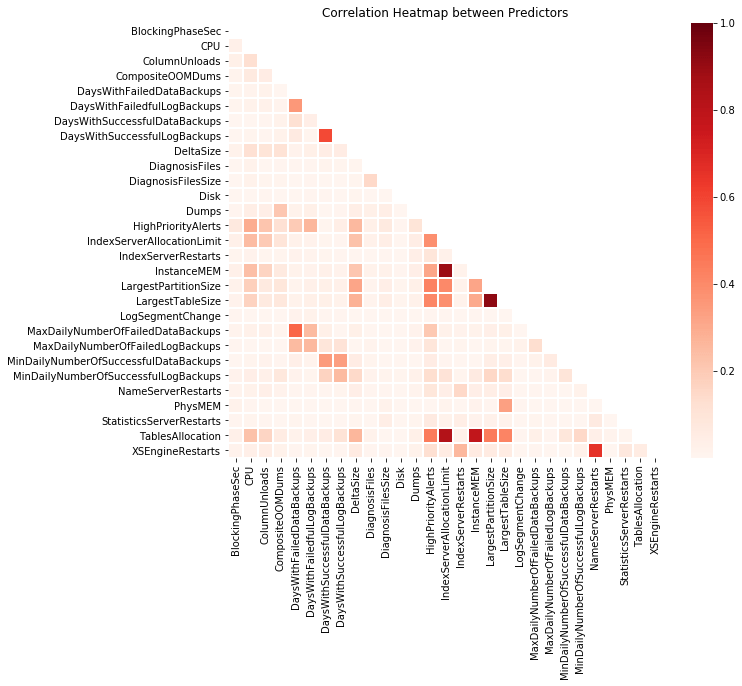
There are many groups of correlated features in the dataset:
- InstanceMEM, IndexServerAllocationLimit and TablesAllocation
- LargestTableSize and LargestPartitionSize
- DaysWithSuccessfulLogBackups and DaysWithSuccessfulDataBackups
- MaxDailyNumberOfFailedLogBackups and MaxDailyNumberOfFailedDataBackups
- NameServerRestarts and XSEngineRestarts
- LargestTableSize and LargestPartitionSize
- HighPriorityAlerts, TablesAllocation, LargestTableSize, LargestPartitionSize, and IndexServerAllocationLimit
This finding of correlated predictors is very useful in case we want to reduce the dimensions later.
Second, we explored the relationship between numerical features and labels.


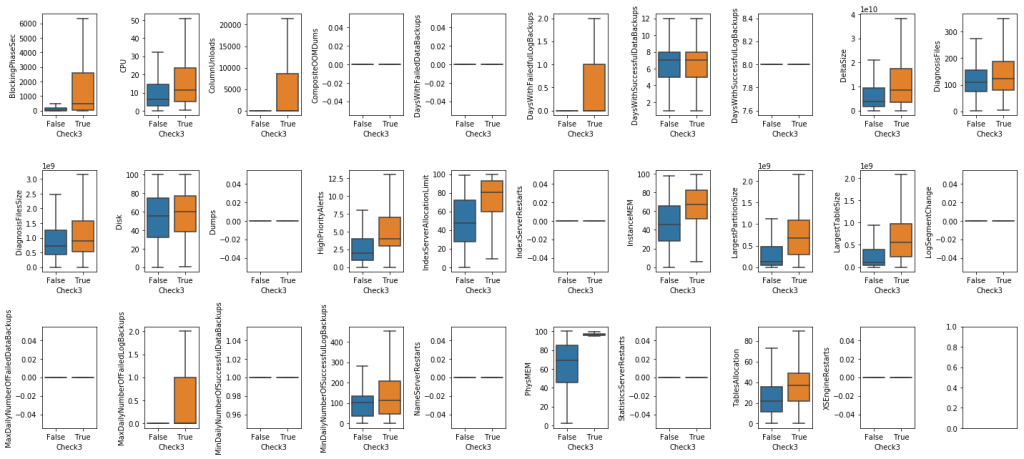


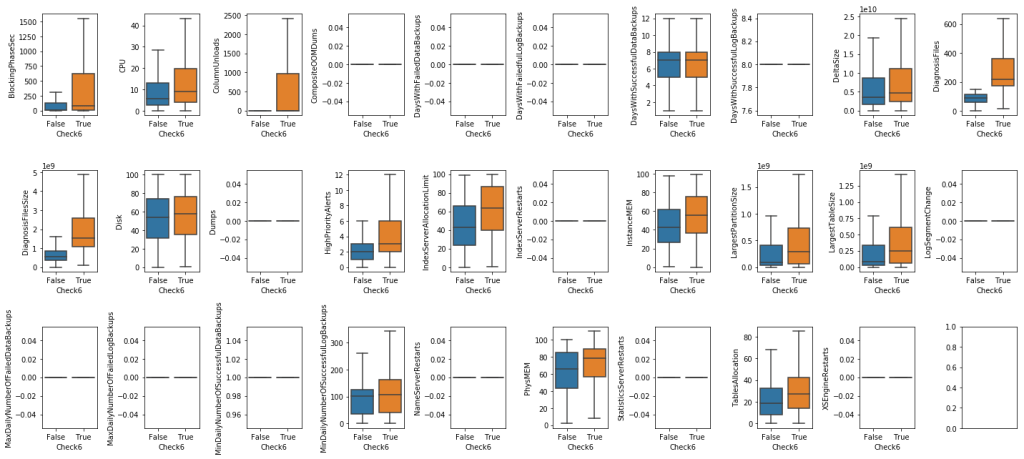
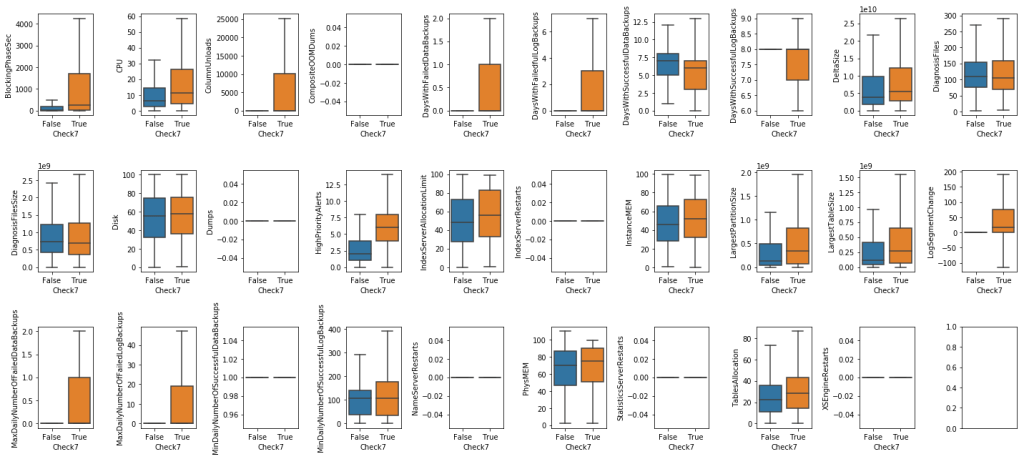
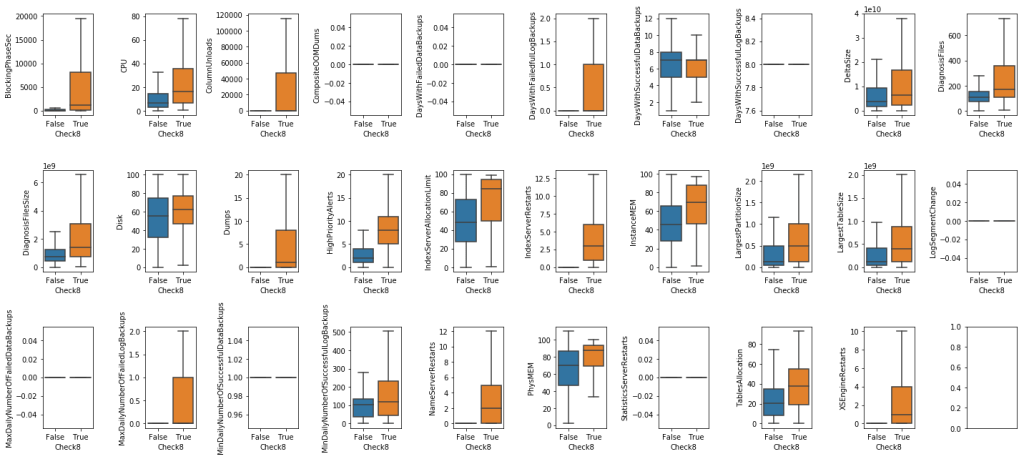
As can be seen from the plots above, there are informative features for classifying labels:
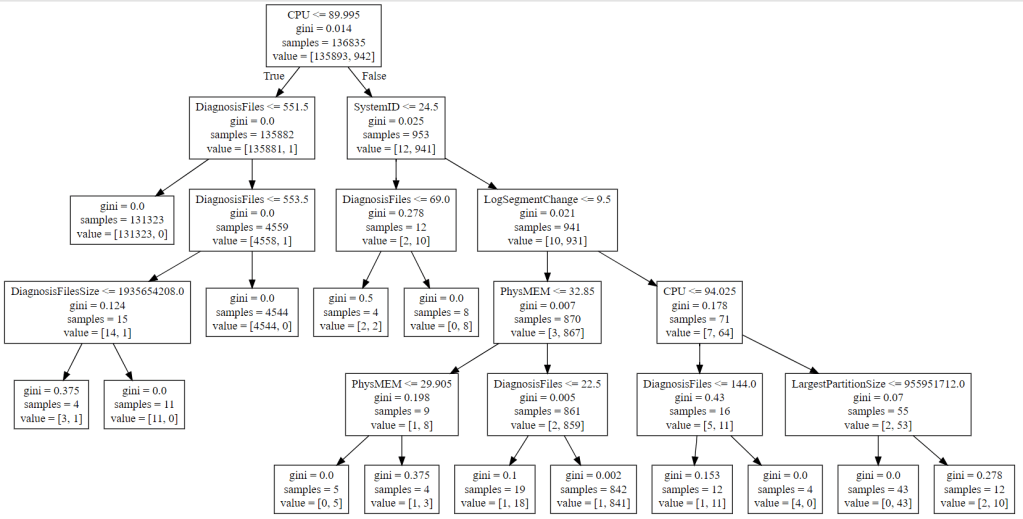
- For Check1: Feature CPU is very useful and can help to separate classes comletely if there are not outliers in the dataset. The instances which have the CPU usage over ~85 will belong to the anomaly class. Besides that, there are other informative features such as HighPriorityAlerts, PhysMEM, etc.
- For Check2: There are many informative features for classifying label 2 such as BlockingPhaseSec, CPU, ColumnUnloads, DiagnosisFiles, IndexServerAllocationLimit, PhysMEM, TableAllocation, etc but they cannot completely seperate classes.
- For Check3: There are many informative features but cannot help to classify classes seperately. They are BlockingPhaseSec, HighPriorityAlerts , ColumnUnloads, LargestTableSize, LargestPartitionSize, etc.
- For Check4: The features which may be useful for classification are BlockingPhaseSec, CPU, HighPriorityAlerts, ColumnUnloads, IndexServerAllocationLimit, InstanceMEM, etc.
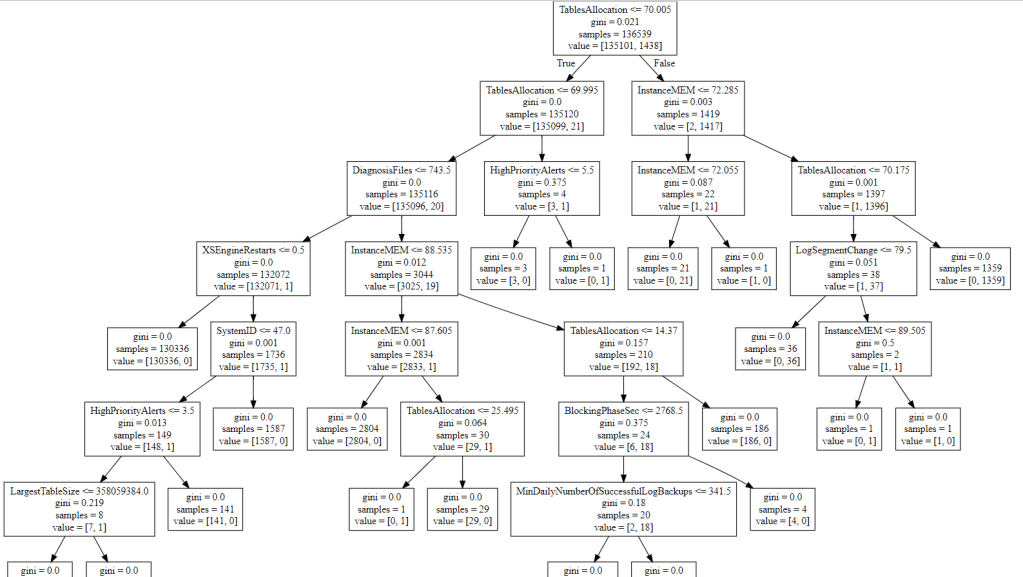
- For Check5: TableAllocation can be a very useful to specify anomaly in label 5. Besides that, InstanceMEM is also a good feature.
- For Check6: DiagnosisFiles and DiagnosisFilesSize are good features to classify the classes.
- For Check7: LogSegmentChange, MaxDailyNumberOfFailedDataBackups, MaxDailyNumberOfFailedLogBackups are good features to classify the classes.
- For Check8: NameServerRestarts and XSEngineRestarts maybe the good features for classification.
Data Preparation
Although not all algorithms fail when the data contain missing data/outliers/etc., there are algorithms which are not robust to unclean data. We created two sets of data for 8 models, one set is not preprocessed and another one is preprocessed.
Error values: Based on the data description, we identified and addressed issues with features’ values. We replaced negative LogSegmentChange values with their absolute counterparts and capped CPU, PhysMEM, InstanceMEM, TablesAllocation, IndexServerAllocationLimit, and Disk values at 100.
Missing values: Since the number of missing values is quite big, we should be carefull before imputing them. To know whether the missing values are related to labels or not, we selected the missing values of a feature and then computed its anomaly ratio. We compared the percent of anomaly of missing features to the percent of whole data and notices that:
- For label Check6, the percent of anomaly of whole data is 29% while the anomaly percent where missing TableAllocation, PhysMEM, InstanceMEM and IndexServerAllocationLimit are 57%, 39%, 38% and 35%, respectively.
- For label Check3, the percent of anomaly of whole data is 3% while the anomaly percent where missing CPU, TableAllocation are 5%, 6%, respectively.
We were not sure about the reasons of missing values, therefore, we did not impute them. We prefer to train models on lack of information data than to train models on incorrect information data. Therefore, in the preprocessed data, we dropped missing rows instead of filling them.
Standardization, Normalization, Outliers: Based on data exploration, we find informative features for each model. For interpretability, we plan to use tree-based and rule-based algorithms that don’t require normalization and are unaffected by variable transformations. Regarding outliers, we retain them during preprocessing for two reasons: 1) Outliers may have a connection to anomalies. 2)Our chosen models, rule-based and tree-based, are robust to outliers.
Although we plotted boxplot to examine the relationship between categorical features and labels, we employed Mutual Information between them and selected the best features which help to reduce the uncertainty in the labels.
Model Selection
For each label, we created 4 datasets:
- The dataset which is not preprocessed, with full features.
- The dataset which is not preprocessed, with selected features based on the mutual information.
- The dataset which is preprocessed, with full features.
- The dataset which is preprocessed, with selected features based on the mutual information.
Although 8 models are 8 different anomalies, its features are similar. Therefore, we implement model selection for only one label and then apply to the others. To save time, we train the models on a subset data instead of whole data.
We trained 8 models using rule-learning algorithm (Bayesian Rule Set) and a tree-based algorithm (Decision Tree).
| Bayesian Rule Set | Decision Tree | |
| Definition | The Bayesian Rule Set consists of rules, with each rule being a combination of conditions. If any rule is met, it predicts an observation as positive; otherwise, it’s labeled as negative. | A Decision Tree is a hierarchical tree structure model. It predicts by repeatedly dividing the data using features and assigning outcomes to the final leaf nodes. |
| Complexity | Finding sparse models is computationally hard, Bayesian Rule Set tries to find the globally optimal solution in the reduced space of rules. Its complexity depends on total number of conditions in the model, which is the sum of lengths for all rules. | The model is to find the locally optimal solution. Its complexity O(nsamplesnfeatureslog(nsamples)). However, Scikit-learn offers a more efficient implementation for the construction of decision trees. Presorting the feature over all relevant samples, and retaining a running label count, will reduce the complexity at each node, which results in a total cost. |
| Interpretation | Interpretation can be challenging due to the probabilistic nature and complex rules. | Easier to interpret, as decisions are made based on feature thresholds and branching logic. |
| Handling imbalanced dataset | The prediction will be biased towards the more frequent class. | The prediction will be biased towards the more frequent class. |
| Handling numerical and categorical Variables | Can handle both numerical and categorical variables. | Can handle both numerical and categorical variables. |
| Handling missing values | This form of models are generally robust to outliers and naturally handle missing data, with no imputation needed for missing attribute values. | Tree-based methods can use the missing value as a unique and different value when building the predictive model. These algorithms are also robust to outliers. Sadly, the scikit-learn implementations of decision trees is not robust to missing values. |

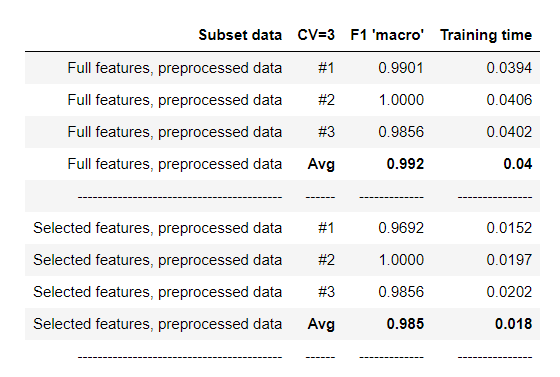
According to the prediction performance and training time of these two algorithms, we decided to use the Decision Tree Classifier and full features for detecting anomalies.
The parameter tunning step using GridSearchCV was also conducted to find the best hyperparmeter for each model (model from 1 to 8).
Result
Here is the prediction result for 8 models (8 anomalies). In general, the predictive performances of these models are very high, especially the model 6 and the model 8 (f1 macro is ~1.0000). The lowest performance is for the model 7 (f1 macro is ~0.8044).
The training time of the models are so small, from 0.4666 seconds to 2.5990 seconds.

As can be seen form the trees below, each anomaly is caused by different reasons in the system such as CPU usage, memory usage, memory allocation, system backup, system restart, etc.






Leave a comment